

Here we are going to see about processing and storing large data sets in an ‘offline-first’ model. So here’s the word ‘offline-first’ is the catch. When you have an ‘online-first’ architecture your app doesn’t need to process a huge volume upfront. So the explained below approach suits the best for ‘offline-first’ use case.
First I tried the conventional way of pumping the large data via http body using URLSession download task. Well the download was easy peasy. Approx. 1 million records were pumped to the download task completion handler.
After downloading the entire data set and converting them as objects and processing (writing to db’s such as realm , core-data etc ) bears a heavy memory foot print on the volatile memory (RAM) due to which low memory warning or termination by iOS occurs on this volume scale. The reason because the entire data set is required by the RAM for holding and RAM needs additional usage for processing it.


As you can see the memory usage is 5. 34 GB. As it was running in simulator it wasn’t a problem. In the case of real device Kaboom, even if it crosses 600 MB in a 1 GB RAM device, the app gets terminated.
So what next, technically there are two broader way to approach this problem, viz,
1. Batch Processing (Classic approach)
In order-to over come above mentioned problem batch processing is recommended classical. By batching, the memory foot print on the volatile memory can be regulated as objects are imported and written to the storage in batches. Batching this 1M to batches of size maximum up-to 20,000 records each is the recommended safe limit. (50 batches). Batching can be done in several ways in line with the backend data grid architecture such that the data pockets are batched when sent to the mobile device further which it will be processed serially in the app.
Basically on each network service request we get a max of 20K records or download a single folder having the entire data set as subfolder of max of 20K records max in each subfolder.
So processing, importing and writing objects to the local storage always happens in batch of the specified size and it is safe for the RAM to process.
Downside: Though this solution works there are key factors linked to it.
Scalability: This solution might not be very easy to scale upwards. Has tight dependency on the backend capabilities and architecture. So basically backend and app cannot be monitored under one umbrella as far as the data is concerned.
Batch processing is also a time consuming one as every second of waiting matters in the digital arena.
2. Persistence storage (Cloud database sync — Modern/clean approach)
The concept is a secure web-socket (see web-socket vs HTTP ) gateway with synchronization for accessing and synchronizing data over cloud database server and the local database in the application.
In our example we are going to see one such product, i.e Couchbaselite Sync Gateway.
Incase you are not aware about Couchbaselite, please seeIntroductionCouchbase Lite is an embedded, NoSQL JSON Document Style database for your mobile apps. You can use Couchbase Lite…docs.couchbase.com
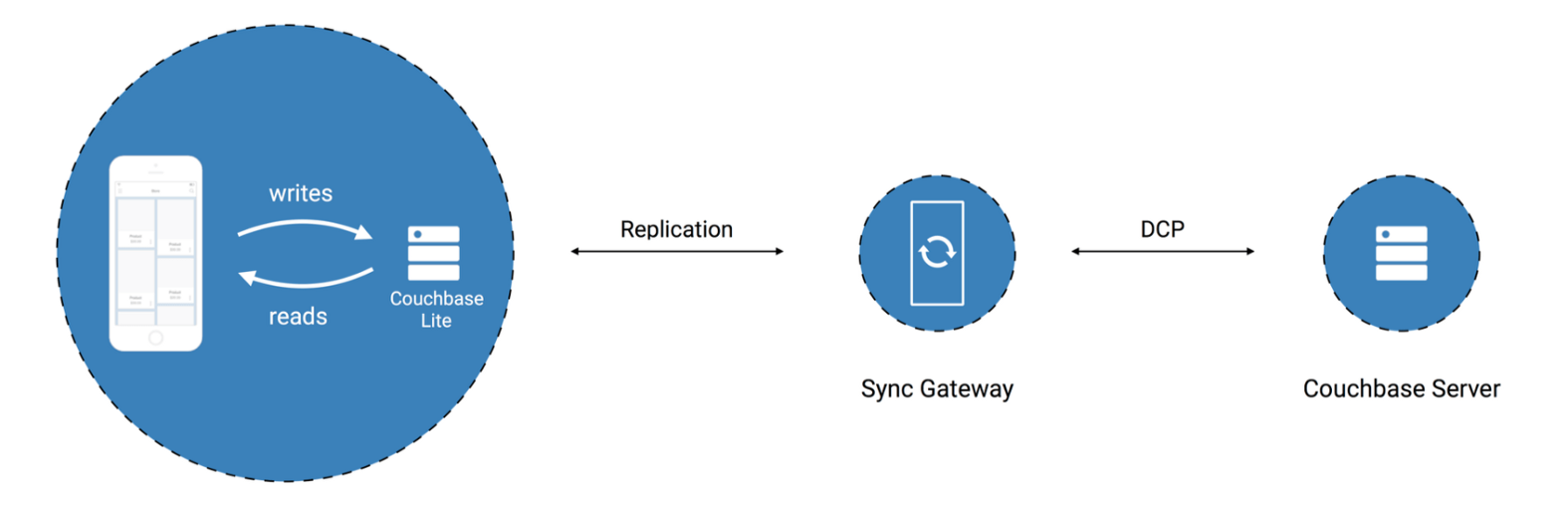
So as you can see in the above architecture devised by Couchbase, the app has local storage with couchbaselite. Data to the couchbaselite is pumped via the sync gateway from the couchbase server. And moreover as the sync gateway writes objects to the couchbaselite database (which resides on the internal storage of the device) directly, there is no overhead or pressure on the RAM for processing the objects (other than to manage the socket connections).
Data to the couchbase server is the written from the server side.
The primary object responsible for pulling the records from the couchbase server is the Replicator class in couchbaseliteswift,

So when the replicator starts, it starts listening to the records in the server and writes them all in the couchbaselite database in the device.

As you can see, replicator downloads all the records from the couch-base sync server. The memory consumption when the replicator downloads all the records is way well in the safe limit of the RAM.
Once the records are placed in the disk, a basic query will fetch you the desired record instantly. However it has to be taken care not to fetch all the records as that gives a pressure on the ram.

As you can, fetching all the records causes a memory heap, where as querying based required conditions is a safe approach.

The above image shows the memory footprint when we fetch based on query.
Conclusion: From the observations we can conclude,
- With Couchbase sync gateway we can safely implement very large data handling in the iOS application and also in a scalable manner with a very safe memory footprint on the iOS device’s RAM.
- As it uses web-sockets the transactions are faster
- Scalable in the ‘offline-first’ mode as when the first time the replicator comes online it downloads all the data and the next time when the app comes online it just checks the delta and downloads the delta alone as the sync gateway takes care of the updates and the delta that needs to be synced.
- When ever a change is triggered from the iOS app client, the replicator class in all the other user’s app will get the change in an instant.(Adhoc- use case)
Thanks to the tutorial on the same topic by
Couch reference
